Ever come across the term “block storage” when looking at cloud services, server specs, or IT infrastructure and wondered what it actually means? You’re not alone! It’s a fundamental concept in the world of data storage, especially crucial for performance-hungry applications like databases and virtual machines.
This friendly guide will break down exactly what block storage is in easy-to-understand terms. We’ll explore how it works behind the scenes, highlight its main advantages, pinpoint where it’s most commonly used, and clarify how it differs from other storage types like file and object storage. Let’s demystify block storage together!
So, What Exactly is Block Storage?
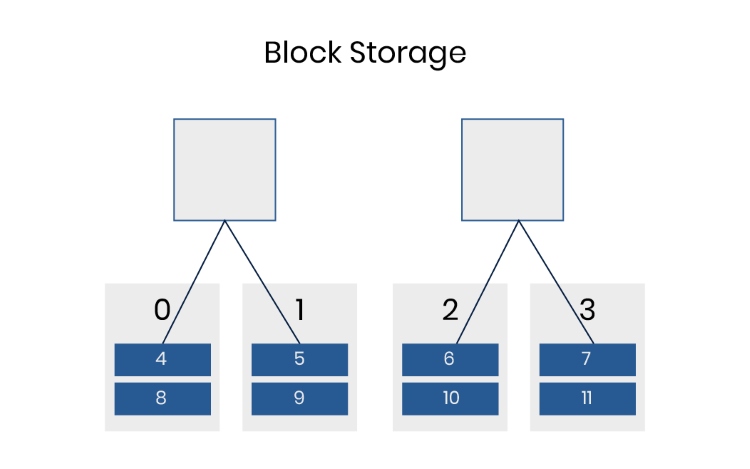
Block storage is a type of data storage that saves data in fixed-size chunks called blocks. Each block acts like an individual hard drive volume and has a unique address, but contains no higher-level metadata like file type or owner.
Think of it like a notebook with uniquely numbered, blank pages. You decide what goes on each page (block) and how to organize the information across pages. The notebook itself doesn’t know if page 5 holds part of an essay or a drawing; it just knows how to find page 5.
This low-level format is often called block level storage or raw storage. It provides the foundation upon which other systems, like file systems, can be built. Operating systems access this storage directly at the block level.
The system managing the storage presents these blocks to servers as individual disk volumes. This allows the server’s operating system complete control over how it uses that space, making it highly flexible.

How Does Block Storage Work?
Understanding how block storage operates helps clarify why it’s suited for specific tasks. It involves how data is organized, how it’s accessed, and the role the operating system plays.
Data Organisation: Fixed-Size Blocks
When you save data to block storage, it’s broken down into these fixed-size pieces or blocks. Common block sizes are often 4KB or 8KB, though this can vary depending on the system configuration.
Each block gets a unique identifier or address. The storage system uses these addresses to locate and retrieve data quickly, regardless of where the blocks physically reside on the storage media (like Solid State Drives – SSDs, or Hard Disk Drives – HDDs).
This method is very efficient for systems that need fast access to specific data segments, like database management systems retrieving records.
Access Methods: SANs and Protocols (iSCSI, Fibre Channel)
Servers typically access block storage over a network using specific protocols. Often, this involves a Storage Area Network (SAN). A SAN is a dedicated, high-speed network separate from the regular user network, designed purely for connecting servers to storage devices.
Two common protocols facilitate this block-level communication over a network:
- iSCSI (Internet Small Computer System Interface): This protocol allows block storage commands to travel over standard Ethernet networks using TCP/IP. It’s popular because it uses familiar networking technology.
- Fibre Channel (FC): This is a high-speed protocol specifically designed for storage networking. It often requires dedicated hardware like Fibre Channel switches and Host Bus Adapters (HBAs), delivering excellent performance and reliability.
These protocols make the remote block storage appear to the server’s operating system as if it were a locally attached drive.
The Operating System’s Role: Formatting and Management
When a server connects to a block storage volume (a logical unit of block storage presented to the server), the Operating System (OS) sees it as a raw disk drive without any structure.
The OS then takes control. It uses volume management tools to partition the disk if needed. Crucially, the OS applies a file system on top of the block volume.
A file system (like NTFS for Windows, or ext4, XFS, ZFS for Linux/Unix) organizes the raw blocks. It creates the familiar structure of files and directories that users and applications interact with. The file system keeps track of which blocks belong to which file.
Key Characteristics & Benefits: Why Use Block Storage?
Block storage offers several distinct advantages, making it the preferred choice for certain types of applications and workloads. Its core strengths revolve around performance, reliability, and control.
Blazing Speed: High Performance (IOPS & Low Latency)
This is often the primary reason for choosing block storage. It generally offers high IOPS (Input/Output Operations Per Second) and low Latency.
- IOPS measures how many read and write operations a storage device can perform each second. High IOPS is crucial for applications handling many small, frequent data requests, like transactional databases.
- Latency is the time delay between requesting data and receiving it. Low latency is vital for applications needing near-instant data access.
Block storage achieves this performance because data paths are often more direct. There’s less overhead compared to file or object storage systems, allowing faster data retrieval and storage. Performance can be further boosted significantly by using SSDs instead of traditional HDDs.
Reliability and Stability for Critical Data
Block storage systems, especially when implemented using SANs with redundant components, are designed for high availability and data integrity. This makes them suitable for enterprise storage needs and mission-critical applications where data loss or downtime is unacceptable. Features like RAID (discussed later) further enhance this reliability.
Flexibility: You Choose the File System
Because block storage presents raw volumes, you have the freedom to choose and apply almost any file system that your operating system supports. This allows you to optimize the storage format for your specific application needs (e.g., XFS for large files on Linux, NTFS for Windows environments).
Granular Control for Applications
Certain applications, particularly database management systems, benefit from the lower-level control block storage provides. They can optimize how data is written to and read from the underlying blocks, bypassing some file system layers for greater efficiency.
Block Storage vs. File Storage vs. Object Storage (Key Differences)
Understanding block storage becomes much clearer when you compare it to the other two major storage types: file storage and object storage. Choosing the right type depends heavily on your specific needs.
Block Storage Recap: Raw, Fast Volumes
As we’ve discussed, block storage deals with data in fixed-size blocks accessed via protocols like iSCSI or FC, often over a SAN. Its main strengths are high performance (IOPS/Latency) and suitability for structured data like databases and VM file systems. It appears as a local disk to the OS.
File Storage (Like NAS): Familiar Folders & Files
File storage organizes data in a hierarchical structure of files and folders, just like you see on your personal computer. It’s commonly accessed using a NAS (Network Attached Storage) device.
NAS devices connect to the standard network and use protocols like NFS (Network File System) (common in Linux/Unix) or SMB/CIFS (Server Message Block/Common Internet File System) (common in Windows).
Multiple users or servers can easily share files stored on a NAS. It’s excellent for shared documents, user home directories, and general-purpose file sharing. It manages file-level metadata (like filename, owner, permissions) directly. However, file storage generally has higher latency compared to block storage.
Object Storage (Like Cloud Buckets): Massive Scalability & Metadata
Object storage manages data as distinct units called ‘objects’. Each object contains the data itself, potentially extensive customizable metadata (information describing the data), and a globally unique identifier (ID).
Unlike the hierarchical structure of file storage or the raw blocks of block storage, object storage typically uses a flat address space. Objects are accessed via APIs (Application Programming Interfaces), usually using HTTP/S commands like those defined by the Amazon S3 API (Simple Storage Service).
Object storage excels at scalability (handling vast amounts of data, trillions of objects) and durability. It’s highly cost-effective for storing large volumes of unstructured data. Common uses include backups, archives, static website content delivery (like images and videos), and data lakes for big data analytics. Access latency is typically higher than block or file storage.
Quick Comparison: Block vs. File vs. Object
| Feature | Block Storage | File Storage (NAS) | Object Storage |
|---|---|---|---|
| Structure | Raw Blocks | Hierarchical (Files/Folders) | Flat (Objects) |
| Access Unit | Blocks / Volumes | Files / Directories | Objects |
| Protocols | iSCSI, Fibre Channel (FC) | NFS, SMB/CIFS | HTTP/S APIs (e.g., S3 API, Swift) |
| Access Method | Mounted Disk (via SAN typically) | Network Share (via NAS typically) | API Calls |
| Performance | High IOPS, Low Latency | Moderate Latency/Throughput | High Throughput, Higher Latency |
| Use Cases | Databases, VMs, Transactions | Shared Docs, User Drives, Apps | Backup, Archive, Web Assets, Big Data |
| Metadata | Minimal (Managed by File System) | Rich (File Attributes) | Rich & Customizable (Object Level) |
| Scalability | Volume Size Limits | File System/Device Limits | Extremely High (Near Infinite) |
Understanding these differences is key to choosing the right storage architecture for your application or workload. They are not mutually exclusive; many organizations use a combination of all three.
Common Use Cases: Where Does Block Storage Shine?
Block storage’s unique characteristics make it the ideal solution for several demanding applications. Its performance and reliability are critical factors in these scenarios.
Powering Databases (SQL & NoSQL)
Databases frequently perform numerous small read and write operations (high IOPS requirement) and need rapid data access (low latency requirement). Block storage directly meets these needs.
Relational databases like MySQL, PostgreSQL, Oracle Database, and Microsoft SQL Server rely heavily on block storage for their data files and logs. Even some NoSQL databases designed for low-latency operations benefit significantly from being deployed on block storage.
Virtual Machine (VM) Disks (Boot & Data)
Block storage serves as the virtual hard drive for Virtual Machines (VMs). When you run a VM using hypervisors like VMware vSphere, Microsoft Hyper-V, or KVM, the operating system for that VM (e.g., Windows Server, Ubuntu Linux) needs block-level access to its boot disk and any additional data disks.
Cloud providers offer block storage specifically for this purpose. Examples include:
- AWS EBS (Elastic Block Store): Provides persistent block storage volumes for use with EC2 instances.
- Azure Disk Storage: Offers high-performance, durable block storage for Azure Virtual Machines.
- GCP Persistent Disk: Delivers reliable, high-performance block storage for Compute Engine instances.
These services allow VMs to function just as if they had local physical drives attached.
High-Performance Computing (HPC) & Transaction Logs
Scientific simulations, financial modeling, and other High-Performance Computing (HPC) tasks often involve intensive computations that require fast access to large datasets. Block storage provides the necessary I/O performance.
Applications that generate frequent transaction logs, such as busy e-commerce platforms or messaging systems, also benefit from the low latency writes offered by block storage.
RAID Configurations
RAID (Redundant Array of Independent Disks) is a technology used to combine multiple physical disk drives into one or more logical units for data redundancy, performance improvement, or both.
RAID operates at the block level, striping or mirroring data across disks. Therefore, block storage devices (like individual SSDs or HDDs within a server or SAN) form the foundation upon which RAID arrays are built.
Are There Any Downsides? (Considerations for Block Storage)
While powerful, block storage isn’t always the perfect fit. There are some potential drawbacks or considerations depending on your environment and needs.
- Complexity: Setting up and managing dedicated SAN infrastructure (especially Fibre Channel) can be more complex and require specialized expertise compared to deploying a simple NAS device for file sharing.
- Cost: High-performance block storage solutions, particularly all-flash arrays (AFAs) using only SSDs, can represent a significant investment. While costs have decreased, performance often comes at a premium.
- Metadata Handling: Block storage itself doesn’t handle rich metadata. This responsibility falls entirely on the file system implemented on top of it, limiting searchable metadata compared to object storage.
- Direct Sharing Limitations: Sharing a single block volume directly among multiple servers simultaneously requires specialized clustered file systems (like VMFS or OCFS2). Standard file systems assume exclusive access, unlike NAS which is built for sharing.
Block Storage in the Cloud Era
The rise of cloud computing hasn’t diminished the importance of block storage; it has just changed how it’s delivered. As mentioned earlier, major cloud providers offer block storage as a fundamental service (IaaS – Infrastructure as a Service).
These cloud-based block storage services (EBS, Azure Disk, Persistent Disk) provide flexibility and scalability. Users can provision volumes of various sizes and performance tiers (e.g., general-purpose SSD, provisioned IOPS SSD, optimized HDD) on demand.
They also typically integrate features like automated snapshots for backup, encryption at rest and in transit, and the ability to easily attach and detach volumes from virtual machine instances. This makes leveraging the benefits of block storage accessible without managing complex physical hardware.
Conclusion: Wrapping Up Block Storage
So, what is block storage? It’s a fundamental storage type that saves data in fixed-size, addressable blocks, appearing as raw disk volumes to the operating system.
Its primary advantage lies in high performance, offering low latency and high IOPS crucial for demanding applications. This makes it the go-to choice for databases, virtual machine file systems, and other transaction-heavy workloads.
Crucially, it differs significantly from file storage (NAS, offering shared file access) and object storage (highly scalable, API-driven storage for unstructured data).
While potentially more complex or costly than other types for certain scenarios, block storage remains a vital component of modern IT infrastructure, both on-premises and in the cloud. Choosing block storage means prioritizing speed, control, and reliability for your most critical applications.
If your applications demand the kind of reliable storage performance discussed, consider where you host them. For high-speed virtual servers built on new-gen dedicated hardware like AMD EPYC Gen 3 processors and SSD NVMe U.2 drives, explore a Vietnam VPS. Expect stable, quality hosting with strong configurations optimized for demanding tasks.