You’ve likely heard the term “microservices” frequently in tech discussions. But what does it really mean? This guide is designed for developers, architects, and operations professionals seeking a thorough understanding of microservice architecture. We’ll explore its definition, core principles, compare it to monoliths, weigh its significant benefits against its considerable challenges, and delve into the essential patterns and technologies that make it work.
What are Microservices?
A single microservice is best understood as a small, autonomous software component focused on doing one specific thing well, usually related to a distinct business capability. For example, in an e-commerce application, you might have separate microservices for user authentication, product catalog management, shopping cart functionality, and order processing.
Each microservice runs independently in its own process. This isolation is key; it means a change or failure in one service ideally doesn’t directly break others. Services communicate with each other over a network, using well-defined APIs (Application Programming Interfaces) or asynchronous messaging systems.
The emphasis is on being “small” and focused. While there’s no strict rule on size (like lines of code), a good guideline is that a service should be small enough to be easily understood, maintained, and potentially rewritten by a small team. Its boundaries are often defined by business domains.

Understanding Microservice Architecture
Microservice architecture, therefore, is the overall structure created by composing an application from these multiple, independent microservices. Instead of one large, indivisible application (a monolith), you have a collection of specialized services working together to deliver the complete functionality required by the end-user or other systems.
This approach inherently creates a distributed system. Components run on potentially different machines and rely on network communication. This distribution is the source of many microservice benefits (like independent scaling) but also many of its challenges (like network latency and complexity).
The key characteristics are loose coupling (services minimize dependencies on each other’s internal workings) and high cohesion (code related to a specific function resides within a single service). This promotes modularity and makes the overall system more flexible and adaptable to change over time.
Why Organizations Choose Microservices?
Despite their complexity, microservices offer compelling advantages that drive adoption, particularly for organizations building large, complex systems or seeking to modernize existing applications. These benefits address common pain points experienced with traditional monolithic architectures, driving tangible business value.
Agility Unleashed: Faster Development and Deployment
Perhaps the most significant driver is increased agility. Small, autonomous teams focused on individual microservices can develop, test, and deploy their updates independently. This drastically shortens release cycles compared to coordinating large, infrequent deployments of a monolith, enabling faster feature delivery and quicker responses to market changes.
Scalability on Demand: Scaling Services Independently
Microservices allow for precise, independent scaling. If your product search service experiences heavy load, you can scale just that service by adding more instances, without touching the user profile or order processing services. This optimizes resource utilization and cost compared to scaling an entire monolith.
Built for Resilience: Improved Fault Isolation
Well-designed microservice architectures enhance system resilience. Because services are independent, the failure of one non-critical service (e.g., a recommendation engine) doesn’t necessarily crash the entire application. Using patterns like the Circuit Breaker helps contain failures, improving overall application availability for users.
Freedom of Choice: Technology Diversity
Microservices embrace technology heterogeneity, often called the polyglot approach. Teams can select the most appropriate programming language, database, or framework for the specific job their service needs to do. A team might use Python for a machine learning service, Java for core transactions, and Node.js for a UI-facing API.
Aligning Teams and Code: Conway’s Law in Practice
Microservices naturally align with Conway’s Law, which states that organizations design systems mirroring their communication structures. By organizing small, cross-functional teams around specific business capabilities (and their corresponding microservices), communication becomes more focused, ownership increases, and development often becomes more efficient.
Embracing Innovation: Easier Adoption of New Technologies
Introducing new technologies or upgrading existing ones is less risky in a microservices environment. A new framework or database version can be piloted within a single service first. This allows teams to experiment and adopt beneficial technologies incrementally without the “big bang” upgrade challenges common in monoliths.
The Technology Ecosystem Enabling Microservices
Microservices don’t exist in a vacuum. Their adoption has been heavily influenced and enabled by advancements in surrounding technologies, particularly containerization, orchestration, cloud computing, and DevOps tooling. Understanding this ecosystem is key to implementing microservices successfully.
Packaging Services: Containerization (Docker)
Containers, popularized by Docker, provide a lightweight way to package an application’s code, libraries, and dependencies together. This creates a consistent, isolated environment ensuring a microservice runs the same way regardless of where it’s deployed (developer laptop, staging, production). Containers simplify building, shipping, and running services.
Managing Fleets: Container Orchestration (Kubernetes)
Running a few containers is easy; managing hundreds or thousands requires Container Orchestration. Platforms like Kubernetes (K8s) automate the deployment, scaling, load balancing, self-healing, and networking of containerized microservices. They handle tasks like placing containers on servers, restarting failed containers, and providing built-in service discovery.
Automating Delivery: CI/CD Pipelines
The ability to deploy services independently and frequently necessitates robust automation. Continuous Integration (CI) tools (like Jenkins, GitLab CI, GitHub Actions) automatically build and test code upon commit. Continuous Deployment (CD) tools then automatically deploy validated services to production, enabling rapid, reliable releases essential for microservice agility.
Leveraging the Cloud: Managed Services (AWS, Azure, GCP)
Cloud platforms like Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP) offer a wealth of managed services that significantly simplify building and operating microservices. These include managed Kubernetes (EKS, AKS, GKE), managed databases, message queues, serverless compute (FaaS), monitoring tools, and more, reducing operational burden.
Taming Communication: Service Meshes (Istio, Linkerd)
As the number of services grows, managing inter-service communication becomes complex. A Service Mesh (like Istio or Linkerd) provides a dedicated infrastructure layer, typically using sidecar proxies alongside each service instance. It handles concerns like traffic routing, load balancing, security (mTLS), circuit breaking, and observability transparently, decoupling these from the application code.
Essential Microservices Patterns for Success
Navigating the complexities of microservices requires leveraging established design patterns. These patterns represent proven solutions to common problems encountered in distributed systems, helping architects and developers build more resilient, scalable, and manageable microservice-based applications. Visual diagrams are highly recommended for understanding these patterns.
Communication Styles: Choosing Wisely
How services talk to each other is a critical design decision:
- Synchronous Communication: One service calls another and waits for a response (e.g., using REST APIs over HTTP or gRPC). This is simpler to reason about initially but creates tighter temporal coupling – the caller is blocked if the callee is slow or unavailable.
- Asynchronous Communication: Services communicate indirectly via messages or events, often using a Message Queue (like Kafka, RabbitMQ, AWS SQS). The sender doesn’t wait for an immediate response. This promotes loose coupling and resilience but introduces complexity around eventual consistency.
Core Architectural Patterns
These patterns address fundamental structural concerns:
- API Gateway: Acts as a single entry point for all external client requests. It routes requests to appropriate downstream microservices, potentially handling concerns like authentication, authorization, SSL termination, rate limiting, and response aggregation. Variations like the Backend for Frontend (BFF) pattern tailor gateways for specific client types (web, mobile).
- Service Discovery: In dynamic environments where service instances come and go (especially with containers), services need a way to find the network locations (IP address, port) of other services they need to call. Patterns include Client-Side Discovery (client queries a registry) and Server-Side Discovery (router/load balancer queries registry). Orchestrators like Kubernetes provide built-in server-side discovery.
Resilience Patterns
These patterns help systems handle inevitable failures gracefully:
- Circuit Breaker: Prevents an application from repeatedly trying to call a service that is known to be failing. After a threshold of failures, the “breaker” trips, failing fast on subsequent calls and potentially redirecting to a fallback, giving the failing service time to recover.
- Other Resilience Patterns: Briefly, the Timeout Pattern prevents waiting indefinitely for a response. The Retry Pattern handles transient failures by automatically retrying calls. The Bulkhead Pattern isolates failures by limiting resources allocated to calls for a specific service, preventing one failing service from consuming all resources.
Data Management Patterns
Handling data across services is a major challenge:
- Database per Service: The cornerstone pattern for loose coupling. Each microservice manages its own private database schema and data, accessible only via its API. This prevents tight coupling through shared tables but necessitates strategies for cross-service queries and consistency.
- Saga Pattern: Manages distributed transactions that span multiple services. It sequences local ACID transactions within each service and uses asynchronous messaging or event choreography to trigger subsequent steps. It requires implementing compensating transactions to handle rollbacks if a step fails.
Observability Patterns
Understanding what’s happening inside a distributed system:
- Distributed Tracing: Assigns a unique ID to external requests and propagates it as calls flow across services. Tools like Jaeger or Zipkin collect timing data for each step, allowing visualization of request paths and identification of bottlenecks or errors across the system.
- Log Aggregation / Centralized Logging: Collects logs from all service instances into a centralized system (e.g., ELK Stack – Elasticsearch, Logstash, Kibana; Splunk; Datadog) for searching, analysis, and alerting. Structured logging formats (like JSON) are highly beneficial here.
- Health Check API: Each service exposes an endpoint (e.g.,
/health) that monitoring systems can poll to check if the service is running and able to process requests. Orchestrators use this for self-healing.
Deployment Patterns
Safely releasing changes to production:
- Blue-Green Deployment: Maintain two identical production environments (“Blue” and “Green”). Deploy the new version to the inactive environment (Green), test it, then switch traffic from Blue to Green. Provides easy rollback by switching back.
- Canary Releases: Gradually roll out the new version to a small subset of users/requests first. Monitor closely for errors or performance issues. If stable, gradually increase traffic to the new version while phasing out the old one. Reduces blast radius of bad deployments.
Microservices vs. Monolithic Architecture: A Fundamental Comparison
Understanding microservices is often easiest when contrasting them with the traditional approach: the monolithic architecture. While monoliths have served us well and still have their place, microservices offer a different set of trade-offs aimed at addressing the challenges faced by large, complex monolithic applications.
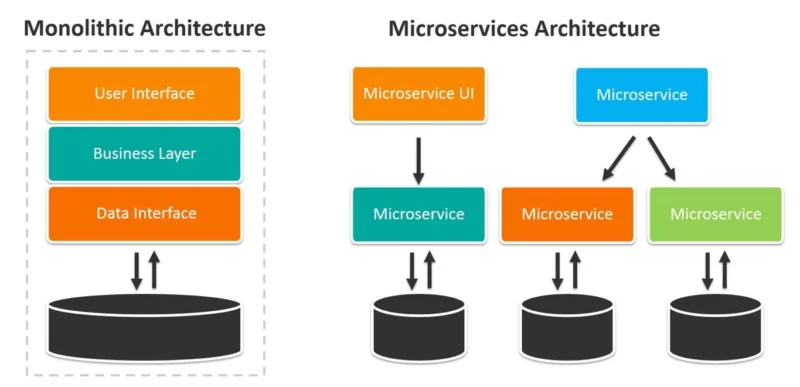
Revisiting the Monolith: Characteristics
A monolithic application is built as a single, unified unit. All its functionalities – user interface, business logic, data access – are typically contained within one large codebase. This entire unit is compiled, tested, and deployed together, often running as a single process.
Development might initially be simpler, as all code is in one place. However, as the application grows, the monolith becomes increasingly complex and tightly coupled. A change in one small part might require testing and redeploying the entire application, slowing down development cycles significantly.
Scaling a monolith often means scaling the entire application, even if only one specific feature is experiencing heavy load. This can be inefficient. Furthermore, technology choices are usually uniform across the entire application, making it difficult to adopt new languages or frameworks incrementally.
Head-to-Head: Key Differences Analyzed
Let’s break down the core differences:
- Deployment: Microservices are deployed independently; a change to one service doesn’t require redeploying others. Monoliths require deploying the entire application for any change, increasing risk and delaying releases.
- Scalability: Microservices allow granular scaling – scale only the services that need more resources. Monoliths must be scaled as a whole unit, which can be resource-intensive and inefficient if only a small part is bottlenecked.
- Technology Stack: Microservices enable technology diversity (polyglot programming/persistence); teams choose the best stack per service. Monoliths typically enforce a single, uniform technology stack across the entire application.
- Fault Tolerance: Failure in one microservice can be isolated (if designed for resilience), minimizing impact on the rest of the application. A critical failure in a monolith can bring the entire application down.
- Development Speed & Agility: Smaller, independent teams working on microservices can often move faster than large teams coordinating changes within a complex monolith. This leads to quicker feature delivery and iteration cycles.
- Complexity: Monoliths centralize complexity within one codebase. Microservices trade this for distributed complexity – managing interactions, data consistency, and operations across many independent services and network boundaries, which is often harder.
Microservices vs. SOA (Service-Oriented Architecture): Subtle but Important Distinctions
Microservices are sometimes confused with Service-Oriented Architecture (SOA), an earlier architectural style focused on exposing reusable business functions as services. While related, key differences exist. Microservices typically emphasize smaller, more focused service boundaries (often aligned with DDD’s Bounded Contexts).
SOA often relied on heavier communication protocols (like SOAP) and middleware like Enterprise Service Buses (ESBs) for orchestration and integration (“dumb endpoints, smart pipes”). Microservices favor simpler protocols (REST, gRPC) and embed logic within services (“smart endpoints, dumb pipes”), promoting decentralization.
Furthermore, microservices often imply decentralized data management and governance, whereas SOA implementations sometimes leaned towards shared databases and more centralized standards. Think of microservices as a more opinionated, often more granular and decentralized, implementation of service orientation principles.
Microservices FAQ: Answering Common Questions
Let’s address some frequently asked questions about microservices to clarify common points of confusion and provide concise answers based on industry understanding.
Defining “Micro”: How Small is Small Enough?
There’s no magic number (like lines of code). A microservice should ideally encapsulate a specific business capability or Bounded Context from Domain-Driven Design. It should be small enough for a small team to manage, understand, and potentially rewrite independently. Focus on cohesion and business boundaries, not just physical size.
Are Microservices a Silver Bullet?
Absolutely not. Microservices are an architectural choice with significant trade-offs. They solve certain problems (scalability, agility for complex systems) but introduce substantial new challenges (distributed complexity, operational overhead). They are not inherently “better” than monoliths; the best choice depends entirely on the specific context.
How is Security Handled in Microservices?
Security becomes more complex in a distributed environment. Key considerations include: securing endpoints (often at the API Gateway), securing inter-service communication (e.g., using mutual TLS – mTLS, often managed by a Service Mesh), managing identity and authorization across services (e.g., propagating JWTs), and implementing defense in depth within each service.
What is the Role of Domain-Driven Design (DDD)?
Domain-Driven Design (DDD) is crucial for effectively defining microservice boundaries. Concepts like Bounded Contexts (identifying distinct domain areas with their own models and language) provide a strong methodology for decomposing a large domain into logical, cohesive units that map well to individual microservices, preventing the creation of a “Distributed Monolith.”
Can Microservices Be Stateful?
Yes, microservices can be stateful, meaning they manage their own persistent data (often using the database-per-service pattern). However, managing state in a distributed, scalable, and resilient way is challenging. Stateless services (which delegate state management elsewhere) are often simpler to scale and manage within an orchestrator like Kubernetes.